#collapse-hide
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import math
from IPython.display import clear_output
from time import sleep
plt.style.use('dark_background')
np.random.seed(44)
xs = np.random.randint(-100,100,100)
ys = xs * np.random.randint(-10,10) + 100 # + np.random.randint(-200,200,50)
cycles = 50
def graph_gradient_descent(values,cycles, figures,step):
plt.figure(figsize=(20,10))
cols = 3
rows = math.ceil(figures/3)
for x in range(1,figures+1):
plt.subplot(rows,cols,x)
plt.scatter(values['x'],values['y'])
plt.scatter(values['x'],values['cycle0'])
plt.scatter(values['x'],values['cycle'+str(x*step)])
labels = ['y','initial','cycle'+str(x*step)]
plt.legend(labels)
plt.ylim(-1000,1000)
plt.xlim(-100,100)1 Why part 2?
I have done a couple blog posts on Gradient Descent for linear regression focusing on the basic algorithm. In this post, I will be covering some more advanced gradient descent algorithms. I will post as I complete a section rather than waiting until I have every variation posted. This is partially to show some popular ones, but the more important thing to understand from this post is that all these advanced algorithms are really just minor tweaks on the basic algorithm.
2 Goal Recap
The goal of linear regression is to find parameter values that fit a linear function to data points. The goodness of fit is measured by a cost function. The lower the cost, the better the model. Gradient Descent is a method to minimize a cost function. Gradient descent is a widely used tool and is used frequently in tuning predictive models. It’s important to understand the method so you can apply it to various models and are not limited to using black box models. This approach will use the sum of squares cost function to take a predicted line and slowly change the regression coefficients until the line is a line of best fit.
This post will cover the algorithms. Part 4 of this series will focus on scaling this up to larger datasets. One of the primary tools of scaling is using stochastic gradient descent, which is just a fancy way to say “just use a subset of the points instead of all of them”.
3 Background
Our goal is to define the equation \(y=\theta_0+\theta_1x\). This is the same thing as \(y=mx+b\). For this post I will use \(y=mx+b\) language with \(m\) being the slope and \(b\) being the y intercept.
Note: In order to adjust \(m\), I will take \(m\) - <\(m\) PathValue> * <adj \(\alpha\)>.
Note: In order to adjust \(b\), I will take \(b\) - <\(b\) PathValue> * <adj \(\alpha\)>.
Each of these advanced algorithms either change the Path Value, or change \(\alpha\). I will show what the calculation for each is for each algorthm is, have a written explanation, and python code that illustrates it.
4 Setup
Here is where I load libraries, define my dataset, and create a graphing function.
5 Basic Gradient Descent
This is the basic gradient descent algorithm that all others are based on. If you are not clear on how gradient descent works, please refer to the background section for a review or Gradient Descent Part 1 Blog Post for more details. I will use this same format below for each algorithm, and change only what is necessary for easier comparison.
5.0.1 Inputs
\(\alpha = learning rate\)
n = number of data points
5.0.2 New Formulas
\(PathValue_m = PathValue_bx\)
\(PathValue_b = y_{pred}-y_{obs}\)
Each variation after this does 1 of 3 things to modify this algorithm: + Adjusts \(\alpha\) by some amount + Adjust \(PathValue\) by some amount. + Adjust both \(\alpha\) and \(PathValue\).
Really logically speaking, what else can you do? These are the only values that are used to adjust our values, so any tweaks must involve those. We can modify number through addition, subtraction, multiplication, and division: If you get stuck, try to get back to those basics.
5.0.3 Python Function
alpha = 0.0005
def gradient_descent(xs,ys,alpha,cycles):
n = len(xs)
adj_alpha = (1/n)*alpha
values = pd.DataFrame({'x':xs,'y':ys})
weights = pd.DataFrame({'cycle0':[1,1,0,0]},index=['m','b','pvb','pvm'])
values['cycle0'] = weights['cycle0'].m*values['x'] + weights['cycle0'].b
for cycle in range(1,cycles+1):
p_cycle_name = 'cycle'+str(cycle-1)
c_cycle_name = 'cycle'+str(cycle)
error = values[p_cycle_name]-values['y']
path_value_b = sum(error)
path_value_m = sum(error * values['x'])
new_m = weights[p_cycle_name].m - path_value_m * adj_alpha
new_b = weights[p_cycle_name].b - path_value_b * adj_alpha
weights[c_cycle_name] = [new_m,
new_b,
path_value_m,
path_value_b]
y_pred = weights[c_cycle_name].m*values['x'] + weights[c_cycle_name].b
values[c_cycle_name] = y_pred
return weights,values
weights, values = gradient_descent(xs,ys,alpha,cycles)
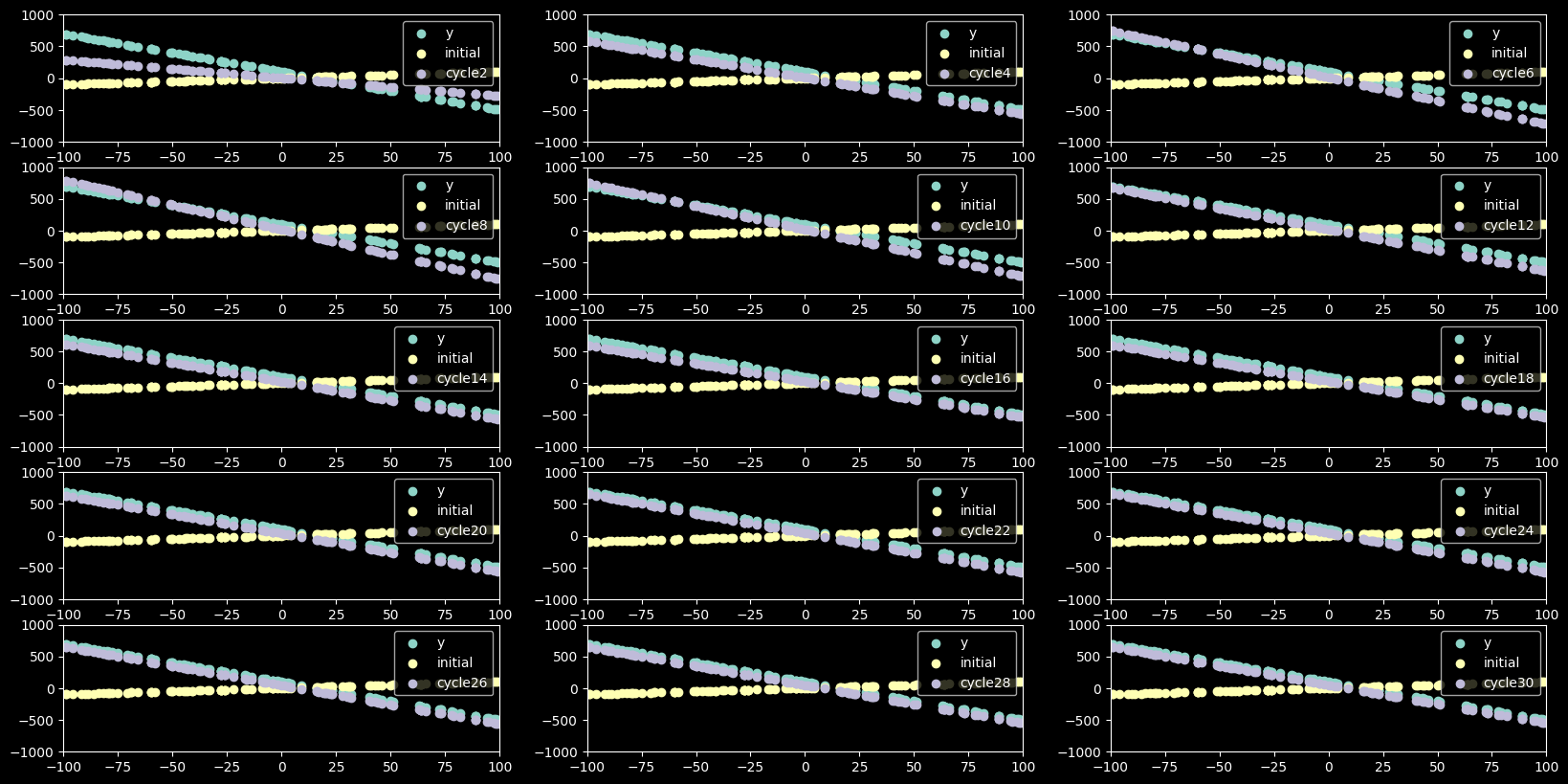
graph_gradient_descent(values,cycles,12,2)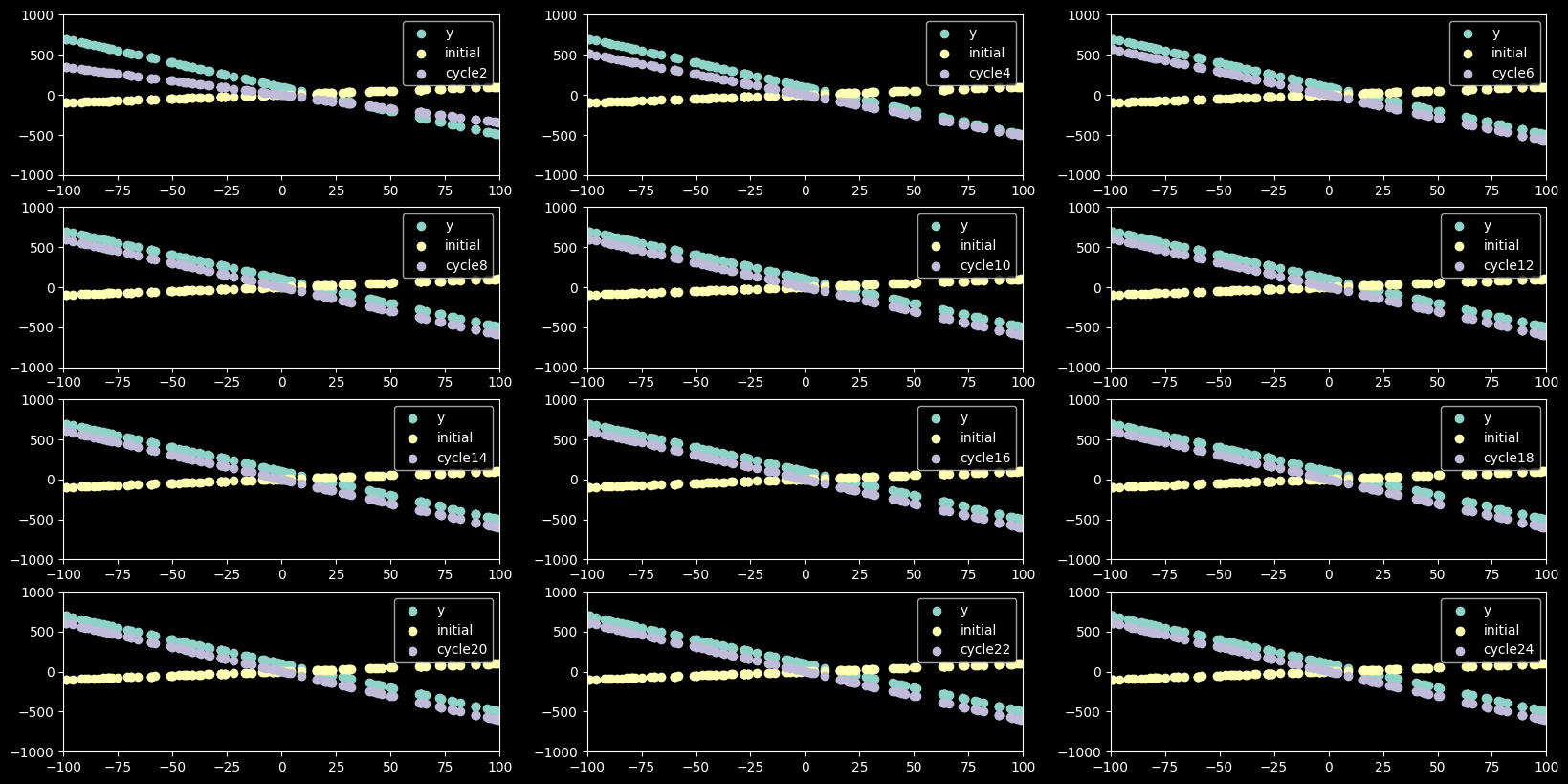
6 Momentum
6.0.1 Concept
The idea of momentum is to use the previous path values to influence the new path value. It’s taking a weighted average of the previous path value and the new calculation. This is referred to as momentum because it is using the momentum from previous points to change the size of the step to take. To control what kind of weighted average is used, we define \(\beta\).
This is useful and effective because we want to have very large steps early on, but the closer we get to the optimal values the lower we want our learning rate to be. This allows us to do that, and if we overshoot then it will average with previous path values and lower the step size. This allows for larger steps while minimizing the risk of our gradient descent going out of control. If you overshoot the optimal weights the weighted average will decrease the step size and keep going, eventually settling on the minimum. A very handy feature!
6.0.2 What is different
What is different: \(PathValue\) has changed and is using a new input \(\beta\)
If you look at \(PathValue_b\) you will notice a change in this formula. \(PathValue_m\) multiplies \(PathValue_b\) by our x value for that point, so it is effected as well.
6.0.3 New Inputs
\(\beta = 0.9\)
6.0.4 New Formulas
\(\alpha_{adj} = \frac{1}{n}\alpha\)
\(PathValue_m\) = \(PathValue_bx\)
\(PathValue_b = (\beta)(PathValue_{b_{previous}}) + (1 - \beta)(y_{pred}-y_{obs})\)
6.0.5 Python Function
alpha = 0.0001
beta = 0.9
def gradient_descent_momentum(xs,ys,alpha,cycles,beta):
n = len(xs)
adj_alpha = (1/n)*alpha
values = pd.DataFrame({'x':xs,'y':ys})
weights = pd.DataFrame({'cycle0':[1,1,0,0]},index=['m','b','pvm','pvb'])
values['cycle0'] = weights['cycle0'].m*values['x'] + weights['cycle0'].b
for cycle in range(1,cycles+1):
p_cycle_name = 'cycle'+str(cycle-1)
c_cycle_name = 'cycle'+str(cycle)
error = values[p_cycle_name]-values['y']
path_value_b = sum(error)
path_value_m = sum(error * values['x'])
if cycle > 1:
path_value_b = (beta) * weights[p_cycle_name].pvb + (1-beta) * path_value_b
path_value_m = (beta) * weights[p_cycle_name].pvm + (1-beta) * path_value_m
new_m = weights[p_cycle_name].m - path_value_m * adj_alpha
new_b = weights[p_cycle_name].b - path_value_b * adj_alpha
weights[c_cycle_name] = [new_m,
new_b,
path_value_m,
path_value_b]
y_pred = weights[c_cycle_name].m*values['x'] + weights[c_cycle_name].b
values[c_cycle_name] = y_pred
return weights,values
weights, values = gradient_descent_momentum(xs,ys,alpha,cycles,beta)
graph_gradient_descent(values,cycles,12,3)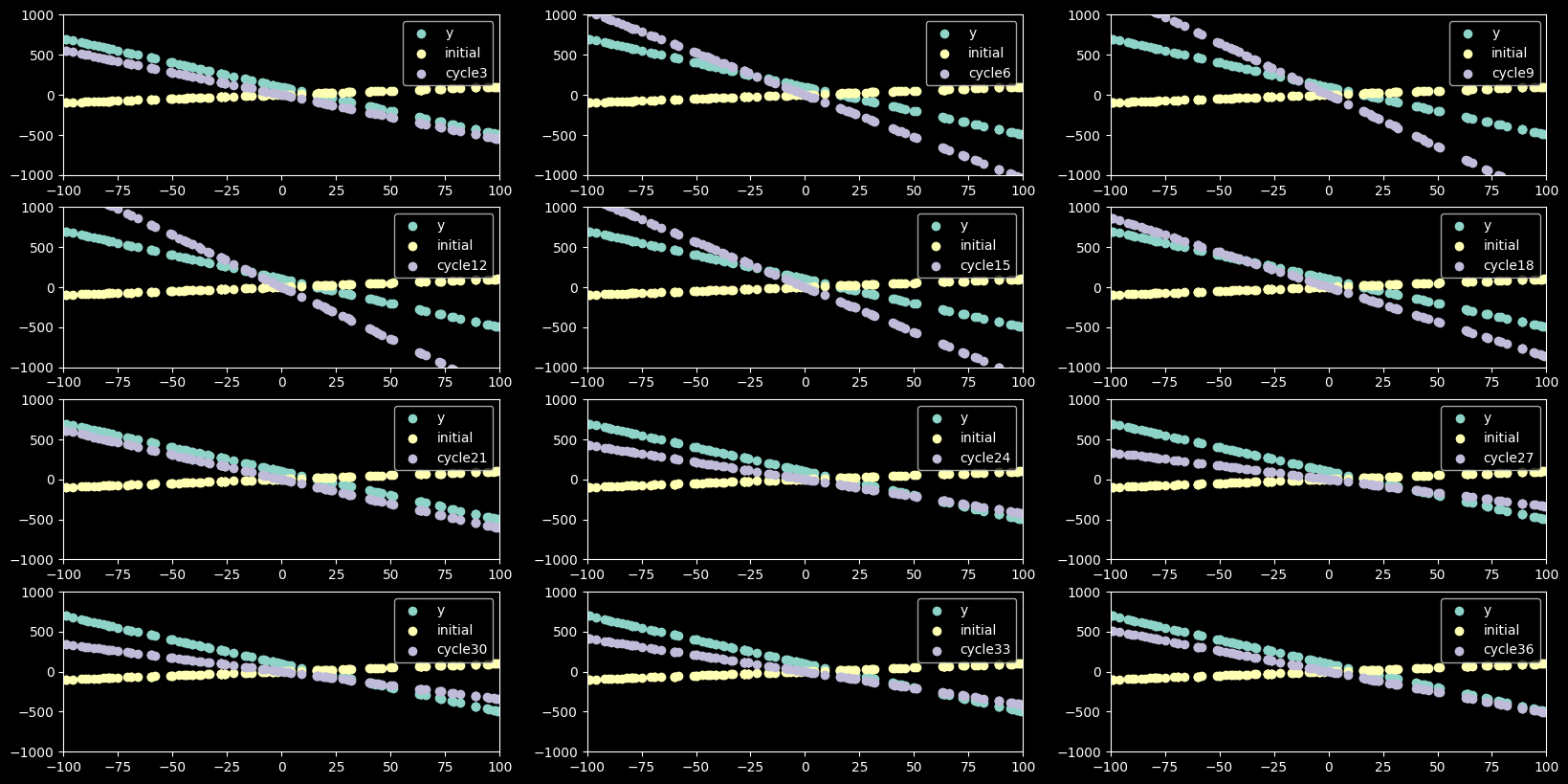
7 RMSProp
7.0.1 Concept
The idea of RMS prop is that we will adjust out learning rate based on how large our error rate it. If we have a very large error, we will take a larger step. With a smaller error, we will take a smaller step. This minimizes the changces that we overshoot the ideal weights. This is accomplished by diving the learning rate by an weighted exponential average of the previous path values. To control what kind of weighted average is used, we define \(\beta\).
This is useful and effective because we want to have very large steps early on with a big learning rate, but the closer we get to the optimal values the lower we want our learning rate to be. This is exactly what RMS prop does - adjust out learning rate based on our error rate. This allows for larger steps with a bigger learning rate while minimizing the risk of our gradient descent going out of control. It has similar benefits of momentum, but approaches it by modifying the learning rath rather than the path value.
7.0.2 What is different
What is different: we have an alpha_multiplier for each variable that is calculated each cycle. When calculating the new value, we divide our learning rate \(\alpha\) by the square root of this alpha multiplier. The alpha multiplier uses a new input, \(\beta\)
Our alpha multiplier is calculated with this formula.
\(alphamultiplier_b = (\beta)(alphamultiplier_{b_{previous}}) + (1 - \beta)((y_{pred}-y_{obs})^2)\)
\(alphamultiplier_m = (\beta)(alphamultiplier_{m_{previous}}) + (1 - \beta)(x(y_{pred}-y_{obs})^2)\)
- Here’s the path value for our Regular Gradient Descent
\(new_m = m - PathValue_m * \frac{\alpha}{n}\)
\(new_b = b - PathValue_b * \frac{\alpha}{n}\)
- Here’s the path value for our RMS Prop
\(new_m = m - PathValue_m * \frac{\alpha}{n\sqrt{alphamultiplier_m}}\)
\(new_b = b - PathValue_b * \frac{\alpha}{n\sqrt{alphamultiplier_b}}\)
8 Python Function
beta = 0.9
alpha = 500
def gradient_descent_momentum(xs,ys,alpha,cycles,beta):
n = len(xs)
adj_alpha = (1/n)*alpha
values = pd.DataFrame({'x':xs,'y':ys})
weights = pd.DataFrame({'cycle0':[1,1,0,0,0,0]},index=['m','b','pvm','pvb','am_m','am_b'])
values['cycle0'] = weights['cycle0'].m*values['x'] + weights['cycle0'].b
for cycle in range(1,cycles+1):
p_cycle_name = 'cycle'+str(cycle-1)
c_cycle_name = 'cycle'+str(cycle)
error = values[p_cycle_name]-values['y']
path_value_b = sum(error)
path_value_m = sum(error * values['x'])
alpha_multiplier_b = abs(path_value_b)**2
alpha_multiplier_m = abs(path_value_m)**2
if cycle > 1:
alpha_multiplier_b = (beta) * weights[p_cycle_name].am_b + (1-beta) * alpha_multiplier_b
alpha_multiplier_m = (beta) * weights[p_cycle_name].am_m + (1-beta) * alpha_multiplier_m
new_m = weights[p_cycle_name].m - path_value_m * adj_alpha / math.sqrt(alpha_multiplier_m)
new_b = weights[p_cycle_name].b - path_value_b * adj_alpha / math.sqrt(alpha_multiplier_b)
weights[c_cycle_name] = [new_m,
new_b,
path_value_m,
path_value_b,
alpha_multiplier_m,
alpha_multiplier_b]
y_pred = weights[c_cycle_name].m*values['x'] + weights[c_cycle_name].b
values[c_cycle_name] = y_pred
return weights,values
weights, values = gradient_descent_momentum(xs,ys,alpha,cycles,beta)
graph_gradient_descent(values,cycles,15,2)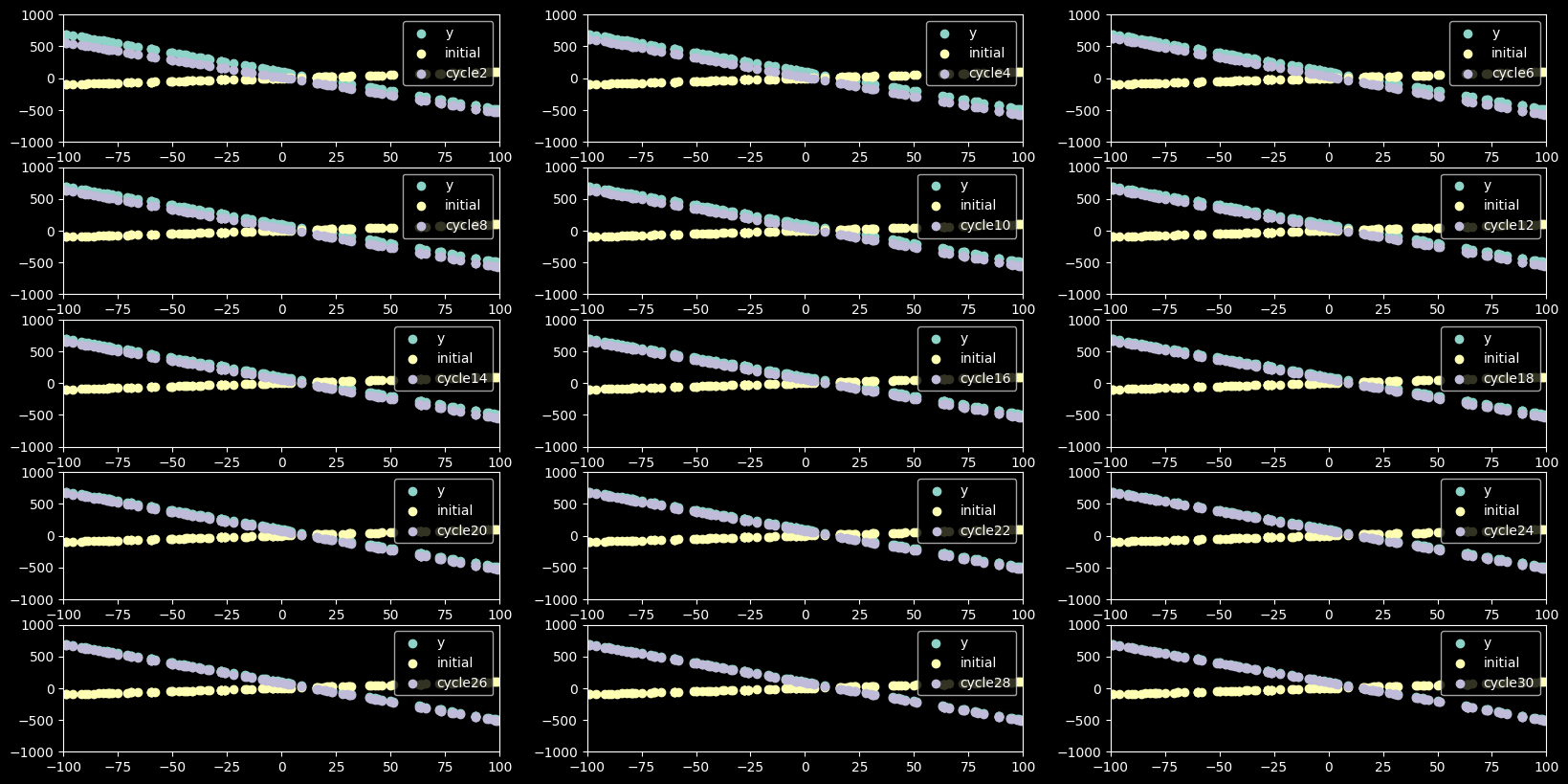
9 Adam
9.0.1 Concept
The idea of Adam is that there are really nice properties to RMS Prop as well as momentum, so why not do both at the same time. We will modify our path value using the momentum formula and we will modify our learning rate using RMSProp formula. To control what kind of weighted average is used, we define beta_rmsprop and beta_momentum. We can have a pretty big learning rate without overshooting.
This is useful and effective because we want the ability to pick up speed like momentum does, but also want to minimize overshooting. Basically we pick up momementum when we are far from the minimum, but we slow down as we get close before we overshoot.
beta_rmsprop = 0.9
beta_momentum = 0.7
alpha = 200
def gradient_descent_momentum(xs,ys,alpha,cycles,beta_rmsprop,beta_momentum):
n = len(xs)
adj_alpha = (1/n)*alpha
values = pd.DataFrame({'x':xs,'y':ys})
weights = pd.DataFrame({'cycle0':[1,1,0,0,0,0]},index=['m','b','pvm','pvb','am_m','am_b'])
values['cycle0'] = weights['cycle0'].m*values['x'] + weights['cycle0'].b
for cycle in range(1,cycles+1):
p_cycle_name = 'cycle'+str(cycle-1)
c_cycle_name = 'cycle'+str(cycle)
error = values[p_cycle_name]-values['y']
path_value_b = sum(error)
path_value_m = sum(error * values['x'])
if cycle > 1:
path_value_b = (beta_momentum) * weights[p_cycle_name].pvb + (1-beta_momentum) * path_value_b
path_value_m = (beta_momentum) * weights[p_cycle_name].pvm + (1-beta_momentum) * path_value_m
alpha_multiplier_b = abs(path_value_b)**2
alpha_multiplier_m = abs(path_value_m)**2
if cycle > 1:
alpha_multiplier_b = (beta_rmsprop) * weights[p_cycle_name].am_b + (1-beta_rmsprop) * alpha_multiplier_b
alpha_multiplier_m = (beta_rmsprop) * weights[p_cycle_name].am_m + (1-beta_rmsprop) * alpha_multiplier_m
new_m = weights[p_cycle_name].m - path_value_m * adj_alpha / math.sqrt(alpha_multiplier_m)
new_b = weights[p_cycle_name].b - path_value_b * adj_alpha / math.sqrt(alpha_multiplier_b)
weights[c_cycle_name] = [new_m,
new_b,
path_value_m,
path_value_b,
alpha_multiplier_m,
alpha_multiplier_b]
y_pred = weights[c_cycle_name].m*values['x'] + weights[c_cycle_name].b
values[c_cycle_name] = y_pred
return weights,values
weights, values = gradient_descent_momentum(xs,ys,alpha,cycles,beta_rmsprop,beta_momentum)
graph_gradient_descent(values,cycles,15,2)