from fastai.vision.all import *
from fastai.data.external import *
from PIL import Image
import math1 Intro
Today we will be working with the MNIST dataset. The goal is going to be to take an image of handwritten digits and automatically predict what number it is. We will be building a Neural Network to do this. This is building off of the previous post where we classified 3s vs 7s. If anything in this post is confusing, I recommend heading over to that post first.
Note
If you get through this and want more detail, I highly recommend checking out Deep Learning for Coders with fastai & Pytorch by Jeremy Howard and Sylvain Gugger. All of the material in this guide and more is covered in much greater detail in that book. They also have some awesome courses on the fast.ai website, such as their deep learning course
2 Load the Data
The first step is to get and load the data. We’ll look at it a bit to make sure it was loaded properly as well. We will be using fastai’s built in dataset feature rather than sourcing it ourself. We will skim over this quickly as this was covered in part 1.
# This command downloads the MNIST_TINY dataset and returns the path where it was downloaded
path = untar_data(URLs.MNIST)
# This takes that path from above, and get the path for training and validation
training = [x.ls() for x in (path/'training').ls().sorted()]
validation = [x.ls() for x in (path/'testing').ls().sorted()]Let’s take a look at an image. The first thing I recommend doing for any dataset is to view something to verify you loaded it right. The second thing is to look at the size of it. This is not just for memory concerns, but you want to generally know some basics about whatever you are working with.
# Let's view what one of the images looks like
im3 = Image.open(training[6][1])
im3
# Let's see what shape the underlying matrix is that represents the picture
tensor(im3).shapetorch.Size([28, 28])3 Linear Equation
We are looking to do wx + b = y. In a single class classifier, y has 1 column as it is predicting 1 thing (0 or 1). In a multi-class classifier y has “however-many-classes-you-have” columns.
3.0.1 Tensor Setup
First we get our xs and ys in tensors in the right format.
training_t = list()
for x in range(0,len(training)):
# For each class, stack them together. Divide by 255 so all numbers are between 0 and 1
training_t.append(torch.stack([tensor(Image.open(i)) for i in training[x]]).float()/255)
validation_t = list()
for x in range(0,len(validation)):
# For each class, stack them together. Divide by 255 so all numbers are between 0 and 1
validation_t.append(torch.stack([tensor(Image.open(i)) for i in validation[x]]).float()/255)# Let's make sure images are the same size as before
training_t[1][1].shapetorch.Size([28, 28])We can do simple average of one of our images as a sanity check. We can see that after averaging, we get a recognizable number. That’s a good sign.
show_image(training_t[5].mean(0))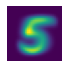
# combine all our different images into 1 matrix. Convert Rank 3 tensor to rank 2 tensor.
x = torch.cat([x for x in training_t]).view(-1, 28*28)
valid_x = torch.cat([x for x in validation_t]).view(-1, 28*28)
# Defining Y. I am starting with a tensor of all 0.
# This tensor has 1 row per image, and 1 column per class
y = tensor([[0]*len(training_t)]*len(x))
valid_y = tensor([[0]*len(validation_t)]*len(valid_x))
# Column 0 = 1 when the digit is a 0, 0 when the digit is not a 0
# Column 1 = 1 when the digit is a 1, 0 when the digit is not a 1
# Column 2 = 1 when the digit is a 2, 0 when the digit is not a 2
# etc.
j=0
for colnum in range(0,len(training_t)):
y[j:j+len(training_t[colnum]):,colnum] = 1
j = j + len(training[colnum])
j=0
for colnum in range(0,len(validation_t)):
valid_y[j:j+len(validation_t[colnum]):,colnum] = 1
j = j + len(validation[colnum])
# Combine by xs and ys into 1 dataset for convenience.
dset = list(zip(x,y))
valid_dset = list(zip(valid_x,valid_y))
# Inspect the shape of our tensors
x.shape,y.shape,valid_x.shape,valid_y.shape(torch.Size([60000, 784]),
torch.Size([60000, 10]),
torch.Size([10000, 784]),
torch.Size([10000, 10]))Perfect. We have exactly what we need and defined above. 60,000 images x 784 pixels for x and 60,000 images x 10 classes for my predictions.
10,000 images make up the validation set.
3.0.2 Calculate wx + b
Let’s initialize our weights and biases and then do the matrix multiplication and make sure the output is the expected shape (60,000 images x 10 classes).
# Random number initialization
def init_params(size, std=1.0): return (torch.randn(size)*std).requires_grad_()
# Initialize w and b weight tensors
w = init_params((28*28,10))
b = init_params(10)# Linear equation to see what shape we get.
(x@w+b).shape,(valid_x@w+b).shape(torch.Size([60000, 10]), torch.Size([10000, 10]))We have the right number of predictions. The predictions are no good because all our weights are random, but we know we’ve got the right shapes.
The first thing we need to do is turn our Linear Equation into a Neural Network. To do that we need to do this twice with a ReLu inbetween.
4 Neural Network
Important
You can check out previous blog post that does thin in a simpler problem (single class classifier) and assumes less pre-requisite knowledge. I am assuming that the information in Part 1 is understood. If you understand Part 1, you are ready for this post!
# Here's a simple Neural Network.
# This can have more layers by duplicating the patten seen below, this is just the fewest layers for demonstration.
def simple_net(xb):
# Linear Equation from above
res = xb@w1 + b1 #Linear
# Replace any negative values with 0. This is called a ReLu.
res = res.max(tensor(0.0)) #ReLu
# Do another Linear Equation
res = res@w2 + b2 #Linear
# return the predictions
return res# initialize random weights.
# The number 30 here can be adjusted for more or less model complexity.
multipliers = 30
w1 = init_params((28*28,multipliers))
b1 = init_params(multipliers)
w2 = init_params((multipliers,10))
b2 = init_params(10)simple_net(x).shape # 60,000 images with 10 predictions per class (one per digit)torch.Size([60000, 10])5 Improving Weights and Biases
We have predictions with random weights and biases. We need to find the right numbers for the weights and biases rather than random numbers. To do this we need to use gradient descent to improve the weights. Here’s roughly what we need to do:
- Create a loss function to measure how close (or far) off we are
- Calculate the gradient (slope) so we know which direction to step
- Adjust our values in that direction
- Repeat many times
The first thing we need in order to use gradient descent is a loss function. Let’s use something simple, how far off we were. If the correct answer was 1, and we predicted a 0.5 that would be a loss of 0.5. We will do this for every class
We will add something called a sigmoid. A sigmoid ensures that all of our predictions land between 0 and 1. We never want to predict anything outside of these ranges.
Note
If you want more of a background on what is going on here, please take a look at my series on Gradient Descent where I dive deeper on this. We will be calculating a gradient - which are equivalent to the “Path Value”
5.0.1 Loss Function
def mnist_loss(predictions, targets):
# make all prediction between 0 and 1
predictions = predictions.sigmoid()
# Difference between predictions and target
return torch.where(targets==1, 1-predictions, predictions).mean()# Calculate loss on training and validation sets to make sure the function works
mnist_loss(simple_net(x),y),mnist_loss(simple_net(valid_x),valid_y)(tensor(0.5195, grad_fn=<MeanBackward0>),
tensor(0.5191, grad_fn=<MeanBackward0>))5.0.2 Calculate Gradient
WE now have a function we need to optimize and a loss function to tell us our error. We are ready for gradient descent. Let’s create a function to change our weights.
First, we will make sure our datasets are in a DataLoader. This is convenience class that helps manage our data and get batches.
# Batch size of 256 - feel free to change that based on your memory
dl = DataLoader(dset, batch_size=1000, shuffle=True)
valid_dl = DataLoader(valid_dset, batch_size=1000)
# Example for how to get the first batch
xb,yb = first(dl)
valid_xb,valid_yb = first(valid_dl)def calc_grad(xb, yb, model):
# calculate predictions
preds = model(xb)
# calculate loss
loss = mnist_loss(preds, yb)
# Adjust weights based on gradients
loss.backward()5.0.3 Train the Model
Note: This is the same from part 1
def train_epoch(model, lr, params):
for xb,yb in dl:
calc_grad(xb, yb, model)
for p in params:
p.data -= p.grad*lr
p.grad.zero_()5.0.4 Measure Accuracy on Batch
def batch_accuracy(xb, yb):
# this is checking for each row, which column has the highest score.
# p_inds, y_inds gives the index highest score, which is our prediction.
p_out, p_inds = torch.max(xb,dim=1)
y_out, y_inds = torch.max(yb,dim=1)
# Compre predictions with actual
correct = p_inds == y_inds
# average how often we are right (accuracy)
return correct.float().mean()5.0.5 Measure Accuracy on All
Note: This is the same from part 1
def validate_epoch(model):
# Calculate accuracy on the entire validation set
accs = [batch_accuracy(model(xb), yb) for xb,yb in valid_dl]
# Combine accuracy from each batch and round
return round(torch.stack(accs).mean().item(), 4)5.0.6 Initialize weights and biases
# When classifying 3 vs 7 in part one, we just used 30 weights.
# With this problem being much harder, I will give it more weights to work with
complexity = 500
w1 = init_params((28*28,complexity))
b1 = init_params(complexity)
w2 = init_params((complexity,10))
b2 = init_params(10)
params = w1,b1,w2,b25.0.7 Train the Model
Below we will actually train our model.
lr = 50
# epoch means # of passes through our data (60,000 images)
epochs = 30
loss_old = 9999999
for i in range(epochs):
train_epoch(simple_net, lr, params)
# Print Accuracy metric every 10 iterations
if (i % 10 == 0) or (i == epochs - 1):
print('Accuracy:'+ str(round(validate_epoch(simple_net)*100,2))+'%')
loss_new = mnist_loss(simple_net(x),y)
loss_old = loss_newAccuracy:18.71%
Accuracy:31.39%
Accuracy:34.11%
Accuracy:34.81%5.0.8 Results
A few key points:
- The Loss is not the same as the metric (Accuracy). Loss is what the models use, Accuracy is more meaningful to us humans.
- We see that our loss slowly decreases each epoch. Our accuracy is getting better over time as well.
5.0.9 This Model vs SOTA
What is different about this model than a best practice model?
- This model is only 1 layer. State of the art for image recognition will use more layers. Resnet 34 and Resnet 50 are common (34 and 50 layers). This would just mean we would alternate between the ReLu and linear layers and duplicate what we are doing with more weights and biases.
- More weights and Biases. The Weights and Biases I used are fairly small - I ran this extremely quickly on a CPU. With the appropriate size weight and biases tensors, it would make way more sense to use a GPU.
- Matrix Multiplication is replaced with Convolutions for image recognition. A Convolution can be thought of as matrix multiplication if you averaged some of the pixels together. This intuitively makes sense as 1 pixel in itself is meaningless without the context of other pixels. So we tie them together some.
- Dropout would make our model less likely to overfit and less dependent on specific pixels. It would do this by randomly ignoring different pixels so it cannot rely on them. It’s very similar to how decision trees randomly ignore variables for their splits.
- Discriminate learning rates means that the learning rates are not the same for all levels of the neural network. With only 1 layer, naturally we don’t worry about this.
- Gradient Descent - we can adjust our learning rate based on our loss to speed up the process
- Transfer learning - we can optimize our weights on a similar task so when we start trying to optimize weights on digits we aren’t starting from random variables.
- Keep training for as many epochs as we see our validation loss decrease
As you can see, these are not completely different models. These are small tweaks to what we have done above that make improvements - the combination of these small tweaks and a few other tricks are what elevate these models. There are many ‘advanced’ variations of Neural Networks, but the concepts are typically along the lines of above. If you boil them down to what they are really doing without all the jargon - they are pretty simple concepts.